Analysis of Algorithms - Part I
|
The following sections are meant to just provide an introduction to algorithm analysis. We won’t delve deep into various algorithms. |
Searching and sorting:
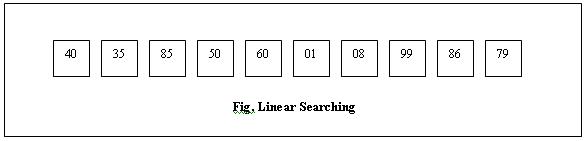
Let’s say we have ten cards lying face down on a table in a single row. Each card has a number between 1 and 100.
If we have to locate the card with number 85, how do you think we would go about the task?
We also know beforehand that the cards are not in sorted order; any number could be present anywhere and the cards have been randomly placed. Because the cards are unsorted we have only one way of searching: pick up each card in the row till we locate number 85.
In computers also, many situations arise where we need to make use of some algorithm for searching through large quantities of data. The simplest form of searching is linear searching (which we have just seen).
An algorithm is a defined sequence of steps for completing a task. Every problem can be solved using different algorithms. Searching data is a problem and linear searching is one algorithm that helps us solve this problem. But not all algorithms are efficient; each one might have its pros and cons. For example in linear searching, if the card we need is at the end of the row then we would have checked all the cards in the row before locating our card. Or suppose the card we are searching for isn’t present in the given set we would have wasted a lot of time in lifting each card. This is the worst case scenario. The best case scenario occurs when the card we require is the first card in the set. Thus in the worst case; if we have ‘n’ cards then we’ll need to make ‘n’ guesses to locate our card. In the best case scenario, we’ll need to make just 1 pick to locate our card.
Note: When we write a computer program we actually implement an algorithm (and before writing any program it is advisable to draft out the algorithm first so that you are clear while coding). For example a program to add two numbers would have the following algorithm:
1.) Obtain the two input numbers.
2.) Perform validations to ensure the sum doesn’t exceed the limits.
3.) Add the two numbers.
4.) Display the result.
In a general sense, algorithm means a sequence of well defined steps. In this section we’ll deal with algorithms that are used to solve particular problems (like searching through data- to achieve this also we require a series of properly defined steps).
Remember: Algorithms are not specific to the type of input data. The linear searching algorithm can be applied while searching for integers, strings, characters, cards (or user defined objects) etc.
A few problems which require algorithms are:
1.) Searching through data.
2.) Sorting of data.
3.) Finding the optimal way to traverse through many places.
4.) Routers connect computers on the internet. They forward data and there are numerous routes possible between two points on the internet. Routers need an algorithm to decide which path to take.
5.) Many scientific problems are based on a set of mathematical equations. Algorithms are required for obtaining the optimal solution for those equations.
Each of these problems has a set of different ways that can be used for solving them (a set of different algorithms are available). But we need some means to measure the performance of an algorithm so that they can be compared. Two parameters that can be used for comparison are space and time.
·
Space- the amount of memory that the program (algorithm) will require.·
Time- the execution time of the program (compile time is not included assuming that programs will not be compiled over and over again).These parameters will depend on the physical hardware; for example an 800Mhz Pentium IV processor will execute a program faster than a 386 machine. The available memory in a computer will also vary from machine to machine. Some machines might have a maximum of 1GB RAM while some might have only 16MB of RAM. But no matter what hardware we use, we would prefer using an algorithm that is efficient and that doesn’t consume unnecessary space. For example: if you had the choice of buying 2 robot dogs; one which is quick and requires only a single 12 Volts battery while the other robot needs two 12 Volts batteries to provide the same performance, which one would you choose? Even if you had a stock of ten batteries you would still prefer the first one; you get to save some batteries which you can use for some other purpose.
Similar is the case with algorithms; even though we might have a more powerful computer we wouldn’t want to use an inefficient algorithm.
Algorithms almost always depend on the size of the input data set. Searching through a stack of 1000 cards is going to consume more time than searching through a stack of 10 cards. The best case scenarios might consume the same time (but we can’t say that an algorithm is great just because in the best case scenario we need very little time).
It would be fair to consider the performance of an algorithm as the input size varies. But we have different scenarios to consider for every algorithm:
1.) Worst case
2.) Best case
3.) Average case
We’ll take up the worst-case scenario (since usually we are interested to know an algorithm’s worst case performance). To measure this, the big-Oh notation is used: denoted as O.
Let’s take some examples to understand big-Oh.
Constant Time:
There are certain instances where the size of the input doesn’t affect the algorithm. Let’s say that we are opening a new store today. We also have a special offer; the first person to come to the shop will get a gift voucher. In this case, irrespective of whether 10 people turn up or 1000 people turn up, we are just going to pick the first person to set foot in our shop. Only the first person gets the voucher. This is the case of a constant-time algorithm; no matter what the size of the input we’ll require the same time to choose the first person. The worst case notation is O(1); i.e. the algorithm depends on a constant (if it depended on the number of inputs then we would have used ‘n’ instead of 1).
Linear-time:
Our linear search algorithm was clearly dependent on the size of the input. If we have 10 cards, then the worst case would be to make 10 picks; if we had 1000 cards, then we would need to pick 1000 times in the worst case. Thus this algorithm depends directly on the size of the input. If ‘n’ is the input then the big-Oh notation is: O(n), i.e. the linear search algorithm depends directly on the size of the input. These are linear-time algorithms because greater the value of ‘n’, greater is the time required.
If n=1 and our algorithm takes 1 minute; then n=10 will require 10 minutes and if n=100 then the algorithm will need 100 minutes (linear dependency).
Binary Search algorithm
Now getting back to our problem of locating the card; how do you think the search can be made more effective? What if the input were in sorted order?
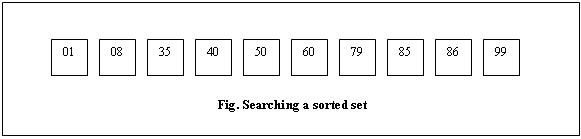
Now the problem is simpler:
|
Round 1: Pick the card in the middle; let’s say 60. Check if the required number (say 85) is greater or less than this. If the required number is greater then ignore the cards below 60. The remaining set would have 60, 79, 85, 86 and 99. |
|
Round 2: Again pick the card in the middle; this time it is 85. Since this is what we need, we can stop the search. If the required card number were less than 60, then we would’ve ignored the higher value cards and restricted our search to 01, 08, 35, 40, 50 and 60. |
The idea is simple: Take the middle card in the set; compare with the required value. If this is our required value then quit searching. Else depending on the required value reduce the search set into half. Again repeat the process (of taking the middle card etc.) within this smaller set. If you’ve noticed after each round we’ll effectively reduce our search area by two. From the initial 10 cards, we’ll come down to 5; then we’ll come down to 3 and so on, after each round.
This search algorithm is called binary searching. In the best case scenario, our card will be the middle card in the search space. In the worst case scenario what do you think will happen?
In linear search algorithm our time depended directly on the value of ‘n’. Clearly in binary search the worst case scenario is better than that of linear-searching. In 10 cards, we needn’t make 10 picks to arrive at the solution; instead a maximum of 4 would be sufficient. The maximum number of times you can divide the search space is log2n (which equals= log10n/log102)
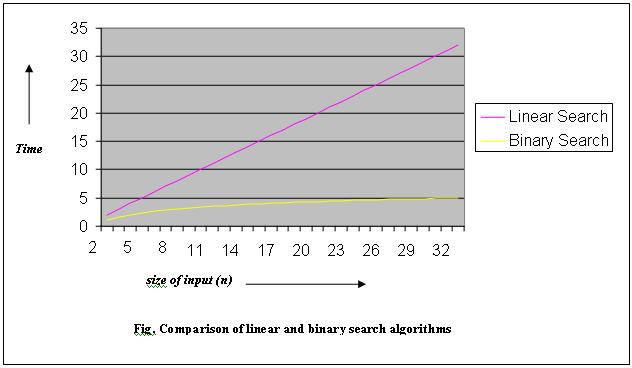
Thus in big-oh notation; the order of the algorithm for binary searching is: O(log2n).
| Go to Analysis of Algorithms - Part II |
| Or go back to the Contents Page 2 |
Copyright © 2005 Sethu Subramanian All rights reserved. Sign my guestbook.