Question and Answers Time
| This chapter is meant to answer some of the questions that were not discussed in the earlier. |
Q.) What is a process?
Every instance of a program is called a process. Suppose in Windows we open “Notepad” ten times, then we’ll have ten Notepad windows on our screen. There is only one Notepad executable file in the system but we’ve invoked this executable ten times (we have ten instances). Each instance is called a process.
In some operating systems, many processes can run at a time (like Windows). Actually it appears to us as if many processes are running simultaneously. The operating system will allocate a small time slot to each process and keep switching from one to the other rapidly (it is so fast that we don’t notice this switching).
In other operating systems like DOS, only one process is executed at a time (i.e. a process can be started only after the current one has completed execution).
Processes are also called ‘tasks’.
Q.) What is an OS?
OS (Operating System) is the software which acts as an interface between application programs (programs we write) and the hardware. It the OS which will execute our programs; in other words, our programs aren’t fed directly to the microprocessor. The OS takes care of this. There are many reasons why an OS is needed as an intermediary.
If 10 processes are running then all these processes will compete for memory. Someone needs to ensure that memory is allocated properly to each of these processes.
All the running processes will want to use the CPU for themselves.
Each program running would require input-output services and there needs to be someone to synchronize this efficiently.
When many processes are running, every process should get some timeslot where it can use the resources (otherwise one process could hijack the processor and prevent all other processes from running).
Some processes might need to be assigned higher priority.
One process shouldn’t be able to manipulate the data of another process.
These are some of the functions that an OS does (scheduling, memory management, setting priorities, I/O management etc).
Q.) More info on linkers and loaders?
To execute a program, the processor needs the executable machine code to lie in main memory (RAM). Whereas when we create an executable file we create this on our hard-disk (secondary storage) which cannot be directly accessed by the CPU. Someone needs to copy or load the program into main memory for execution and this job is performed by the loader.
When a code is compiled, or when a code is assembled, the equivalent object code produced assumes that the program will be placed at memory location 0 (zero) of main memory (because the linker can’t predict beforehand where the OS will place the program in memory). But the OS won’t load programs at memory location 0. And even if it did load the program at location 0 we would still have problems. If we have 10 programs, and we want to run all 10 programs at the same time, obviously all 10 programs cannot occupy memory location 0! Which brings out another important point: not only don’t we know at which location a program will begin but we also don’t have the entire main memory available for use. If our PC were designed such that at a time only 1 program can run, then it is fair to assume that the program which is running will have the entire main memory to itself. But this isn’t the case; in fact the OS itself needs to occupy some part of main memory. So no program would be able to occupy the main memory completely.
Absolute loader:
One method to solve this problem is to use some memory address other than 0 at the time of linking. For example the linker could decide to use 1500 as the starting memory address (or some provision could be provided such that the programmer can specify a starting address in the program itself). The loader would now simply attempt to place the program at main memory location 1500. If that memory location is currently occupied then it’ll have to try again later. This is an absolute loader. It just takes the code and loads it into main memory.
Relocating Loader:
Let’s go back to the initial problem: all programs can end up anywhere in main memory. But since they are created with the assumption of starting at location 0, there needs to be someone who will change the starting value; or in other words someone needs to offset the entire program from memory location 0 by some fixed amount. This is known as relocation.
Let’s take an example:
You may wonder why we need to worry so much about this but it helps to understand how things work in the background.
In a high-level language, we would say:
int x = 1;
x = x + 5;
The compiler, when converting to object code would write something like this:
1. Allocate a memory address for the variable x (say location 1500).
2. Move 1 to location 1500.
3. Add 5 to the value stored at location 1500 and store the result in location 1500.
If you note, everything is written in terms of a memory address (in fact we’ve ended up with just memory locations and constants). It is quite possible that the memory location for data (variables) is allocated just after the code.
|
Memory used for storing the code |
|
Memory allocated for variables |
We could customize the diagram as:
|
int x = 1; x = x + 5; |
|
Memory space for ‘x’ |
Let’s assume that each of the instructions occupies 5 bytes. Thus:
|
Position in memory (in terms of bytes) |
Instruction |
|
0 |
Move 1 to location allotted for x (location 10) |
|
6 |
Add 5 to the value stored at location allotted for x and store the result in the same location (location 10). |
|
10 |
Memory allotted for variable ‘x’. |
Since the compiler will create code assuming that the starting address is location 0, the first instruction is placed at byte 0. Memory for ‘x’ is byte number 10 onwards.
Let’s assume that this is the executable file (which has been created by the linker). The OS wouldn’t permit the program to start at memory location 0 (that location might be reserved for something else). Thus now the program needs to start elsewhere. To start somewhere else, we’ll need to offset all memory locations in the program. Let’s say that the memory location from 8000 onwards is vacant. The loader will now offset the entire program by 8000 and then load the program into main memory. Thus our table will effectively become:
|
Position in memory (in terms of bytes) |
Instruction |
|
8000 |
Move 1 to location allotted for x (location 8010) |
|
8006 |
Add 5 to the value stored at location allotted for x and store the result in the same location (location 8010). |
|
8010 |
Memory allotted for variable ‘x’. |
This kind of a loader is called a relocating loader; it relocates the code in main memory (the problem is that the loader has to check each instruction of the code and perform the required offsetting).
Relocating using a hardware register:
To reduce the burden of a relocating loader, we can use the CPUs internal registers for relocating. In our example the first program instruction should be:
“Move 1 to location allotted for x (register value + 10)”.
Similarly every instruction will depend on the value held in the register. So if the code has to be relocated to 8000, then the value 8000 needs to be placed in this base register.
We’ve so far discussed how loaders work in simple operating systems (like the old version of MS-DOS etc). Modern operating systems (like the latest version of Windows, Unix/Linux) make use of virtual memory (which involves activities like paging and segmentation). Discussing this topic is beyond the scope of this book (for reference you could use a book dealing with computer system architecture or a book on operating systems). In these systems, the loader will need to perform some more additional work in loading a program into main memory.
To sum up: the loader is part of the operating system and it is responsible for loading an executable file into main memory. Our program is stored in the hard-disk (secondary storage) which is not directly accessible by the processor. A program can be executed only when it is loaded into main memory and the loader is responsible for this.
Q.) What is system software and application software?
A.) Software which acts as an interface to computer hardware is system software. Software used to develop applications is also system software. Example: Operating system, loaders, compilers etc.
Software used for other purposes like text editors, music players etc. are called application software. Example: web browsers, calculator, word processors etc.
Q.) Is the hard-disk directly accessible by the CPU?
A.) No. Secondary memory (which includes the hard disk; floppy disk; CD-ROM) cannot be accessed directly by the processor. The processor can only access main memory directly (i.e. main memory can be directly accessed because it is directly connected to the main memory via an address bus) whereas the processor is not connected to the hard disk directly. This is the reason why a program that has to be executed needs to be first loaded into main memory at the time of execution.
The number of address lines in the processor determines the maximum amount of main memory which can be accessed by the processor. A CPU with 8 address lines can access up to 28 memory locations (or 256 bytes of main memory).
Q.) If secondary storage is not accessible then how does the processor access it?
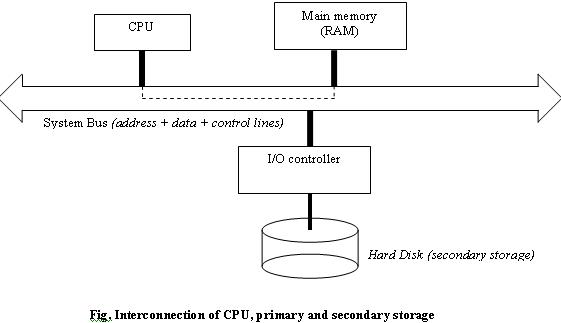
The illustration below would help understand the relation between the CPU, main memory and secondary storage.
A bus is nothing but a group of wires; each wire can be used to transmit one bit and the system bus consists of address and data bus. As the name suggests, addresses are sent on the address bus and data is sent/received on the data bus.
Processor and main (primary) memory:
The processor and main memory are connected to the same bus. Let’s say the processor wants to access memory location 1500.
It would say (through the control bus): “Send me the data at this memory location”
And it would pass the memory location 1500 on the address bus.
On receiving the control signal the main memory will respond by placing the data at 1500 onto the data bus. Then the processor can read the data from the data bus.
All this is possible because the CPU and RAM are connected to the same system bus.
Processor and hard disk:
The problem is obvious; hard disk and CPU are not directly connected. An intermediary device called an I/O controller is in charge of the hard disk and it is this mediator who can be accessed by the CPU. There are many reasons why we use I/O controllers; if we didn’t have them then the CPU would need to worry about directly interacting with these devices (and each I/O device behaves and operates differently). Just like the operating system hides the low-level processor details from us, an I/O controller specific internal details of the I/O device from the CPU (isn’t it easier to program in C++ than in machine language!).
The diagram also explains why the CPU can access the primary memory faster than secondary storage (primary memory is directly connected).
Q.) Is a program divided into different regions?
A.)
·
·
·
·
·
Q.) If I were to make a declaration and definition as follows:
int i=4;
Now in which part of memory will the value of ‘i' be stored in? Will it be in the RAM?? And they say that when we use the ‘new’ operator, memory is taken from the ‘heap’…Is the heap made use of only when the ‘new’ operator is used or can a program make use of the heap in any other way? How does heap differ from stack? Or are they the same? And what is free-store?
When you say memory, we always refer to the RAM. If you have done a course in microprocessor programming you will learn about it. The stack is basically part of the RAM and whenever the program has to branch elsewhere, it will store the return address in the stack. There are many other uses for the stack as well. Now when a parent process asks the operating system to create a child process, the OS allocates space for the child process's code, stack, and data (variables, whose values are given in the program itself). These regions are just memory blocks. The orders in which these blocks exist and the amount of memory purely depends on the OS implementation. Hence a programmer should not be bothered about it. The 'stack' is used to allocate temporary variables. All local variables are temporary variables. All global variables are allocated in the 'data' region. So where did this term 'heap' come from? Heap is a region of memory which is used by 'malloc' (this is an operator similar to ‘new’ and was used in C) and 'new' to allocate memory. When the OS allocates memory, it usually doesn’t do so in a count of bytes. Usually the OS allocates memory to a process in terms of 4KB. Hence when a process needs 100 bytes, the OS gives it 4KB. The 'malloc' and 'new', consider this as the 'heap'. They allocate memory from the 'heap'. When the heap gets over, again the OS is requested for more memory. All this happens transparently; so it is hard to see it before your eyes. Actually this term 'heap' is kind of getting wiped away. It got introduced in MSDOS where the 'heap' referred to all the memory from the last block allocated to a process to the end of memory. This was so because, MSDOS was not a multitasking OS and it didn’t have any protection from user processes. So that was some background information. Coming back to the question,
int i = 4;
If the above declaration was done locally (i.e. within a function), then the allocation is done on the stack. If it is done globally it is in the 'data' section. There is another section called 'bss' which is the un-initialized data, which is similar to 'data'.
There is one more point to note. Sometimes we have a region of memory called as ‘free store’. Sometimes this would be the same as the ‘heap’ but sometimes it could be different. If they are different then there are certain things you have to note. When you use the C++ dynamic memory operators (new and delete), these will operate on the free store. When you use the C operators (malloc and free) they will operate on the ‘heap’. What you have to take care of is not to mix up ‘new’ with ‘free’ and ‘malloc’ with ‘delete’. Suppose the ‘heap’ and ‘free store’ are different, then you will be allocating space in one region and freeing up memory elsewhere. So always use ‘new’ along with ‘delete’ and ‘malloc’ along with ‘free’.
One more important thing; C Standards doesn’t document what I've explained to above. Though this is the convention that is generally followed by most of the C/C++ compilers, a programmer should never wonder where in memory his variable is living. Rather he should think, “what is the scope of a variable?”. That is better programming practice. Usage of global variables should be only after thorough review of the problem.
Q.) Executable formats, what are they and are there many formats?
Just as we have different operating systems, we have different executable formats. What does a format mean? An executable file is not directed at the microprocessor but rather at the operating system. Remember that the operating system is the one which acts as an interface between our program and the hardware. So the OS expects its input to be in a specific format.
Each OS expects an executable file to be in a specific format. In DOS it’s the exe format, in Windows the PE (portable executable) format, in Linux/Unix the ELF (executable and loadable file format) or the a.out format (which was the initial format in Unix). Why bother about this? Actually we don’t need to bother about them but it is one reason why a DOS executable file won’t run on Linux. Linux expects the executable format to be in a structure different from that of DOS.
Q.) Who decides on the size of the stack?
This is again operating system dependent. Every operating system has a specific executable file format. Like in MSDOS you have EXE file format. The old executable format of Linux was 'a.out'. Now the native format is ELF for most of the Unixes. So at the time of compilation, the compiler computes the amount of stack you'd need and it puts in the respective fields of these executable files. Mind you, these executable files are not fully executable. They have a header part, which says where the 'code' section is, where the 'data' section is, how much stack is needed, how much memory to allocate, what are the regions that need not be loaded into memory and so on. As a rule, a C/C++ programmer when writing for a Standard implementation should not be bothered about setting the stack and such. These were an issue only in MSDOS. But still some compilers provide you non-standard features to control the size of the stack. Like the variable 'extern int _staklen' in Turbo C/C++.Supposing you set _staklen = 0x1000;
then the compiler after compilation, when generating the EXE file, will write in the EXE header that you need a stack of '_staklen' bytes. When you execute the executable, the OS will read this header first to load your program. It'll see how much space you need and will allocate it. Then it'll load the respective sections of your program into the respective regions of memory. So, usually it is better not to bother about changing stack settings.
Q.) Can I call a function from within a function?
The main ( ) function does call other functions. Similarly you can call other functions also from within a function. See the example below:
#include <iostream>
using namespace std;
void sum(int a, int b)
{
cout<<endl<<"The sum is : "<<a+b;
}
void input( )
{
int x,y;
cout<<endl<<"Enter the two
numbers : ";
cin>>x>>y;
sum(x,y);
}
int main( )
{
input( );
return 0;
}
The code will compile and run properly. You will get errors if you try to define a function within another function. The compiler will say that local function definitions are illegal. For instance in the above program you cannot define the function input ( ) within the main ( ) function.
Q.) Assume that I am declaring a constant using #define (say something like PI). Does the #define act like a function? Will the #define take up memory space itself?
No, the #define's will not occupy any space in memory. They are preprocessor directives. i.e they are processed before compilation. When you compile a program, there are different stages; the first one is pre-processing where directives such as these can be expanded. So these are decided at compile time and not at run time.
Check out the following code:
#define X 100
int main( )
{
const int mark = 20;
int y,z;
y = X;
z = X + mark;
return 0;
}
In the above code, at the time of compilation all occurrences of 'X' will simply be replaced by '100'. But on the other hand when I define 'const int mark', it means that 'mark' is a variable whose value won’t change. So the compiler allocates some memory for the 'const int'. After preprocessing the code would look as below:
int main( )
{
const int mark = 20;
int y,z;
y = 100;
z = 100 + mark;
return 0;
}
Q.) What is a library? Is it a collection of header files?
A library file contains functions, which can be called from your code. The header files usually contain only the function declarations (function header) while their implementation is present in the library files. Just have a look at stdio.h or conio.h.; they contain tons of functions but their internal coding (function definition) will not be present. The actual functions exist in the library, which is precompiled but not linked. All functions like printf, scanf, gets, puts, etc. are present in the library. We call them in our programs but we can’t include the library just like that. We have to link our file with the library. If you are using Turbo C++, the compiler automatically does this for you (it might be a file called CS.LIB). But you can also do this manually. In some compilers we will have an option in Project Settings to mention the library files that want to link.
Q.) Where should the ‘const’ keyword be placed?
const int i=5;
int const j=4;
Which one is correct?
Both are acceptable. You can place the ‘const’ keyword before the data type or after the data type. But be careful about placing the ‘const’ keyword when you are using pointers.
int x,y;
int *const p1=&x; //constant pointer
int const *p2; //not a constant pointer
x=y=5;
p2=&y;
*p2=6; //Not allowed - we cannot modify the
value at p2.
p2=&x; //Allowed because p2 is not made a
constant pointer
The placement of the ‘const’ keyword will determine whether the pointer is a constant pointer or not.
Q.) I get the following errors when attempting to compile my program (‘Time’ is a class that has private members called ‘hours’ and ‘minutes’):
'hours' cannot access private member declared
in Class 'Time'
'minutes' cannot access private member declared in Class 'Time'
and, 'operator << is ambiguous'
These errors point to the line "ostream & operator<<(ostream & os, const Time & t)"
in my source code. The << operator has been overloaded using friend functions. Why can’t a friend function access the private members of the class? I am currently using Microsoft Visual C++.
A.) If you use some other compiler (other than VC++) you won’t have this problem. Actually this is a bug in Microsoft VC++ version 6.0. They have released a service pack to rectify this problem.
The problem (the bug) is because of ‘using namespace std;’ If you avoid this statement and use iostream.h you won’t have the problem. Another option is to define the overloaded operator << within your class itself (instead of defining it outside the class using the scope resolution operator).
Check out the following website for details about the problem as well as an explanation about the bug and the service pack.
http://support.microsoft.com/default.aspx?scid=kb;EN-US;q192539
Q.) What is name-mangling?
All C++ compilers make use of name mangling. When the compiler reads through the source code and encounters a function name, it stores the details about the function in a table (called a symbol table). For example if we have a function:
void sub (int, int);
the compiler will store this function in its symbol table. But functions in C++ are name mangled, i.e. the function name stored by the compiler is not the same one as given by us. The compiler may store it as:
sub_int_int
Thus whenever the compiler encounters a function call to sub ( ) it will retrieve the appropriate definition for the function at compile-time. Name mangling permits C++ to implement function overloading. Let us say we have another function with the same name ‘sub’:
void sub (double,double);
The compiler will store this as
sub_double_double
Thus whenever there is a statement calling the function sub ( ), the compiler will check the data types of the arguments and call the correct function.
C compilers do not implement name mangling and thus they do not support function-overloading. Different C++ compilers (supplied by different vendors) implement name mangling in a different way but the bottom-line is that all C++ compilers implement name mangling.
Go back to the Contents Page 2
Copyright © 2005 Sethu Subramanian All rights reserved. Sign my guestbook.